


Google indexing is a critical part of SEO. If your website isn’t indexed properly, it won’t appear in search results, limiting its reach and visibility. In this blog post, we’ll explore the most common Google indexing issues and provide actionable solutions to solve them. This will ensure your site gets the visibility it deserves.
Quick Answer
Google indexing issues occur when Googlebot fails to properly crawl and index a website’s pages. Common problems include blocked pages, slow load times, duplicate content, and incorrect robots.txt settings. To fix these, ensure your website is crawlable, optimize page speed, and check for any crawl errors in Google Search Console.
Understanding Google Indexing Issues
Google indexing issues can range from minor glitches to significant errors that impact your website’s visibility. Indexing is the process by which Googlebot scans your website and adds pages to its index for search engine results. If something goes wrong during this process, your pages may not show up in search results, leading to lower traffic and visibility.

Here are some common Google indexing issues:
-
Blocked Pages
-
Crawl Errors
-
Slow Load Time
-
Duplicate Content
-
Incorrect Robots.txt Configuration
Let’s take a deeper dive into each of these issues and how to fix them.
Blocked Pages -
What Are Blocked Pages?
Blocked pages occur when Googlebot is unable to access certain pages on your website. This could be due to various reasons, such as a misconfigured robots.txt file or restrictive HTTP headers.
How to Fix Blocked Pages
-
Check your robots.txt file: Ensure that important pages aren’t accidentally blocked. You can use Google Search Console’s Robots Testing Tool to verify that Googlebot can crawl your site.
-
Fix HTTP Headers: Ensure that the HTTP headers do not contain any “noindex” directives, which tell search engines not to index a page.
Crawl Errors -
What Are Crawl Errors?
Crawl errors happen when Googlebot attempts to access a page but encounters an issue, such as a server error or a page not found (404 error). These errors prevent Google from indexing your content.
How to Fix Crawl Errors
-
Use Google Search Console: Regularly check for crawl errors and fix any broken links or server issues.
-
Create a custom 404 page: Ensure that users and Googlebot can easily navigate when they encounter a broken link.
-
Ensure proper server configuration: Sometimes, crawl errors can be caused by slow servers or misconfigured hosting.
Slow Load Times -
How Do Slow Load Times Affect Indexing?
Google prioritizes websites that load quickly. Slow-loading pages can lead to poor user experience and may result in Googlebot not being able to fully crawl your website.

How to Fix Slow Load Times
-
Optimize images: Use image compression tools to reduce image size without losing quality.
-
Use a Content Delivery Network (CDN): CDNs can reduce load times by distributing content across various servers around the world.
-
Minify CSS and JavaScript: Reduce the size of your CSS and JavaScript files to speed up page rendering.
Duplicate Content -
What Is Duplicate Content?
Duplicate content occurs when multiple pages on your website have the same or similar content. This can confuse search engines and affect your site’s rankings.

How to Fix Duplicate Content
-
Use canonical tags: Implement the rel=”canonical” tag on pages with similar content to tell search engines which version is the preferred one.
-
Consolidate duplicate pages: Merge similar content into a single page or ensure that each page provides unique value.
-
Fix URL parameters: If URLs with different parameters are causing duplication, make sure that Googlebot only indexes the correct version of the URL.
Incorrect Robots.txt Configuration -
What Is a Robots.txt File?
The robots.txt file tells search engines which pages to crawl and which ones to avoid. Incorrect settings can block important pages from being indexed.
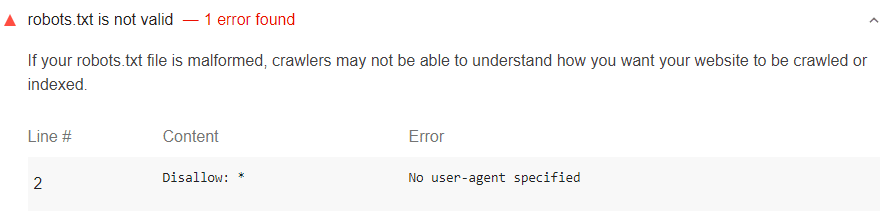 How to Fix Incorrect Robots.txt Configuration
How to Fix Incorrect Robots.txt Configuration
-
Review your robots.txt file: Make sure that the file doesn’t unintentionally block important pages or sections of your site.
-
Check your crawl budget: If Googlebot is crawling unnecessary pages, it may prevent other important pages from being indexed.
Step-by-Step Guide to Solve Indexing Issues
To resolve indexing issues effectively, follow this structured process:
-
Audit Your Website: Regularly check Google Search Console for crawl errors, blocked pages, and other issues.
-
Fix Crawl Errors: Resolve 404 errors, broken links, and server issues that prevent Google from crawling your site.
-
Optimize Page Speed: Minimize images, use a CDN, and optimize scripts to improve page load times.
-
Check Robots.txt: Review your robots.txt file to ensure that Googlebot can crawl the necessary pages.
-
Resolve Duplicate Content: Use canonical tags, consolidate duplicate pages, and ensure unique content.
By following these steps, you can address most Google indexing issues and ensure that your pages are indexed correctly.
Ways to Improve Your Ranking -
Fixing indexing issues is the first step, but to improve your ranking, focus on SEO strategies such as optimizing content, obtaining high-quality backlinks, and improving user experience. These efforts will ensure your site performs well in search engine rankings.
FAQ Section
What is Google indexing?
Google indexing is the process by which Googlebot crawls and adds pages to Google’s search index. If pages are not indexed, they won’t appear in search results.
How do I check if my website has indexing issues?
You can use Google Search Console to check for crawl errors, blocked pages, and other indexing issues.
Why is my page not being indexed by Google?
Your page may not be indexed due to issues like crawl errors, blocked pages, slow loading times, or duplicate content.
How can I fix blocked pages on my website?
Check your robots.txt file and ensure that it isn’t unintentionally blocking important pages. You can also check the HTTP headers for any “noindex” directives.
Final Summary -
Google indexing issues can prevent your website from ranking in search results. Common problems include blocked pages, crawl errors, slow load times, and duplicate content. By following the steps outlined in this blog post, you can fix these issues and ensure that Googlebot can crawl and index your website effectively.
Regular monitoring through Google Search Console, optimizing page speed, and ensuring proper robots.txt configurations are key to solving these problems. Fixing indexing issues is just the start—optimizing for better rankings is an ongoing process that involves continuous improvement.






Thanks for sharing indexing problem in google tips and tricks. It may be helpful for my website. Very nice post, its quite different from other posts.
I have been having indexing issues, but i believe if i implement this, all will be fixed. Thanks in all
Great thing that you have shared.
But Still i m facing Indexing Problem by following Above Steps.
Kindly help me out.
The things who have mentioned are very convincing and will certainly work.
Thanks so much for the post. Really looking forward to read more.
Really informative blog article. Really Great.
You have put everything perfect in it. It’s different from which it looks amazing. I hope you will continue to blog ahead.
Thanking you for give us very useful information. looking forward to read more.
I used these tips..Thnks